Structural Equation Modelling (SEM): The Philosophy
Oleh: Ir. Togar Alam Napitupulu, MS., MSc., Ph.D
Kata kunci pertama pada judul yang akan kita bahas adalah Modelling (Pemodelan). Tentu hasil dari kegiatan pemodelan adalah Model. Apa itu Model? Model adalah abstraksi dari suatu dunia nyata (an abstraction of a real world) dalam satu issu yang menjadi pokok perhatian tentu dengan manfaat tertentu (purposive).
Teladan1 – A demand model: Dunia nyata tentang faktor-faktor yang menentukan atau mempengaruhi permintaan terhadap suatu produk tertentu (Y) misalnya. Tentu banyak sekali faktor2 dalam dunia nyata yang mempengaruhi permintaan terhadap suatu produk. Antara lain adalah Harga dari produk itu (P), Pendapatan dari konsumen (I), Harga dari produk substitute (Ps), harga dari produk komplemen (Pc), dan banyak lagi yang lain. Sebagai peneliti, saya ingin me-model atau meng-abstraksikan faktor2 (variabel2) yang mempengaruhi permintaan terhadap produk tersebut hanya harga dari produk tersebut (P). Dengan kata lain bagi kita sebagai peneliti menganggap variable lainnya seperti Pc, Ps, dan Income (I) tidak penting atau tidak relevan. Nah, dalam model kita, kita abstraksikan bahwa hanya P lah yang mempengaruhi Y; sedang dalam dunia nyata banyak lagi variable yang mempengaruhi Y.
Latihan: Dari segi variable yang mempengaruhi permintaan (Y) ada berapa model (abstraksi) yang bisa kita bentuk, dari variabel2 yang tersedia di atas? — – Suatu model, apakah cukup hanya mendaftar atau mengasumsikan atau menghipotesiskan variabel2 yang mempengaruhi saja? Hal berikutnya yang perlu di hipotesaiskan adalah bentuk hubungan pengaruh antara variable yang mempengaruhi dan yang dipengaruhi; Apakah ada pengaruh langsung atau tidak langsung (mediating atau intervening)? Apakah ada pengaruh dalam bentuk feedback atau pengaruh balik? Apakah ada variable yang memoderasi hubungan2 antara variable tersebut? Ini kita sebut structure dari model itu; – kata kunci kedua.
Sekarang kita bahas mengenai structure dari model yaitu bentuk hubungan dari variabel2 dalam suatu model. Dalam modelling, khususnya untuk ilmu2 sosial dan managemen, struktur sering direpresentaikan dalam bentuk gambar. Sebagai contoh, kalau model kita hanya P yang dipresumsikan sebagai variable yang mempengaruhi Y, maka biasanya digambar sebagai berikut (Gambar 1):
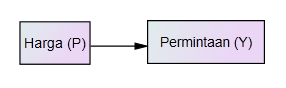 Gambar 1. Struktur dengan satu variable independent (yang mempengaruhi)
Gambar 1. Struktur dengan satu variable independent (yang mempengaruhi)
Tanda panah artinya ada pengaruh dari P terhadap Y. Sebaliknya, kalau pada model kita hipotesiskan bahwa ada pengaruh dua variable P dan I terhadap Y, maka struktur dari model kita secara grafis menjadi sbb. (Gambar 2),
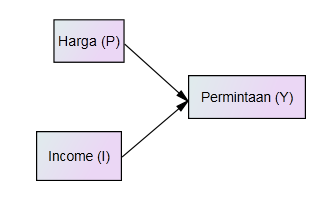 Gambar 2. Struktur dengan dua variable independent
Gambar 2. Struktur dengan dua variable independent
Perhatikan, bahwa struktur dari model kita bisa banyak tergantung pada pre-sumsi (hipotesis) dari peneliti. Masih kemungkinan struktur yang lain adalah, misalnya kita hipotesiskan bahwa Income mempengaruhi harga (tentu harus ada landasan teorinya), maka gambar struktur modelnya menjadi (Gambar 3),
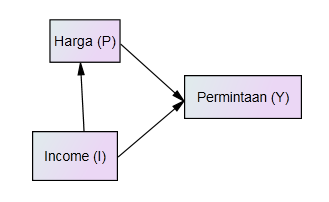 Gambar 3. Struktur dengan dua variable independen, satu langsung (direct) dan satu tidak langsung (indirect – mediating)
Gambar 3. Struktur dengan dua variable independen, satu langsung (direct) dan satu tidak langsung (indirect – mediating)
Bisa saja kita sebagai peneliti mengasumsikan hubungan P dengan Y pada Gambar 1 “tergantung” atau dimoderasi oleh jenis kelamin konsumen JK. Maka modelnya secara grafis menjadi sebagai berikut (Gambar 4), Misalnya sebagai kibat karakteristik tertentu dari produk itu, permintaan tergantung pada apakak kosumen laki-laki atau perempuan; Bisa saja perempuan akan membeli lebih banyak bila harga turun dibandingkan dengan laki-laki.
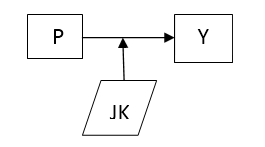
Gambar 4. Model dengan Moderting Variable (JK)
Karena banyak kemungkinan struktur model yang bisa dibangun (tentu harus ada landasan teorinya), maka ini disebut pemodelan (modelling). Selanjutnya, pertanyaan berikutnya tentu adalah model yang mana yang kita pilih. Atau tepatnya model mana yang lebih merepresentasikan dunia nyata (real world). Sebelum kita membahas bagaimana memilih model yang lebih tepat merepresentasikan the real word, masih ada kelemahan dari representasi struktur model dengan gambar seperti di atas. Pertama, hubungan antara variable hanya dengan panah, yaitu yang menunjukkan varabel yang mana yang mempengaruhi yang mana. Tapi bentuk hubungan tersebut masih bisa banyak pilhan. Sebagai contoh, apakah hubungan tersebut linear, atau kuadratik, atau bentuk hubungan yang lain? Sebagai tahap awal, representasi model dengan gambar sudah cukup, terutama untuk menjelaskan kepada para pengguna model nantinya, misalnya pimpinan di perusahaan. Namun untuk keperluan analisis dan pengolahan data, diperlukan model dalam bentuk persamamaan matematik/statistika.
Model dengan persamaan (Equations) matematk/statistika untuk Gambar 1 misalnya adadlah sbb:
Y = β0 + β1 P + Ɛ1 ………………………………………………………. (1)
Dalam ilmu statistika, model ini disebut model Regressi Linear. Linear dalam parameternya, β0, dan β1), bukan dalam variable P nya. Persamaan itu mengatakan bahwa Y tergantung P, atau bahwa Y dipengaruhi P, dan besar pengaruhnya adalah sebesar β1, yaitu, apabila P berubah satu unit maka Y akan berubah sebesar β1 unit. Sedangkan arah dari pengaruhnya adalah tergantung dari parameter (koefisien regressi) β1. Apabila ia positif, maka pengaruhnya adalah searah, i.e., kalau P naik, maka Y juga akan naik; sebaliknya bila negatif, maka pengaruhnya bertolak belakang, i.e., kalau P naik, maka Y akan turun. Tentu, karena model itu adalah model permintaan, maka kita harapkan koefisien β1 ini negatif.
Persamaan regressi untuk model yang kedua (Gambar 2) adalah menjadi sbb:
Y = β0 + β1 P + β2 I + Ɛ2 …………………………………………………….. (2)
Selanjutnya persamaan regressi untuk model ketiga (Gambar 3) menjadi dua persamaan sbb,
Y = β30+ β31 P + β32 I + Ɛ3 ………………………………………………………. (3)
P = β40+ β41 I + Ɛ4 …………………………………………………………………. (4)
(Catatan: setiap variable yang kena panah diwakili satu persamaan regressi di mana variable independennya adalah variable-variabel dari mana panah bersumber)
Persamaan regressi untuk model ke empat dengan moderating variable, pertama untuk kasus dimana varibel moderatornya adalah categorical (misalnya, laki, perempuan; tiga kategori tingkat Pendidikan, tidak tamat sekolah, tamat SD &SMP, tamat SMA, dan tamat sarjana), harus kita tambahkan atau perkenalkan variable dummy. Kalau kategorinya ada dua, maka dummy variabelnya cukup satu, misalnya Jenis Kelamin (JK) utuk gender. Kalau kategorinya n, maka kita harus ciptakan atau tambahkan n-1 variabel dummy untuk menangkap ke n kategori tersebut. Tapi untuk saat ini sementara kita perkenalkan satu dummy dulu untuk yang dua kategori gender, variabel JK. Model regressi untuk Gambar 4 sekarang menjadi sebagai berikut:
Y = β0 + β1 P + β2 JK + β3 JKP + Ɛ1 ………………………………………………………. (5)
Di mana JKP adalah variable baru yang merupakan/menangkap interaksi antara JK dan P dan nilainya merupakan perkalian antara kedua variable itu, dan JK adalah dummy dengan nilai,
Perhatikan, keempat model persamaan regressi di atas sekarang tidak hanya menunjukkan pengaruh lagi, tapi juga sudah bentuk pengaruhnya, yang dalam hal ini adalah hubungan linear dalam parameter atau koefisien regressinya (βi), disamping besar (the magnitude) dari pengaruhnya, yaitu βi sendiri. Sebenarnya model regressi ini bisa mengakomodasi yang tidak linear, tapi dalam variabelnya; misalnya, bisa saja Price (P) kita model dengan kuadratik atau P2, tapi data yang diinput harus dalam bentuk kuadrat. Atau bentuk persamaannya bahkan eksponensial misalnya (yang lebih cocok untuk demand) tapi harus ditransformasi dulu ke persamaan linear dalam koefisien regressinya. Kedua, dengan representasi model dalam bentuk persemaan matematik/regressi seperti ini, kita diperlengkapi dengan alat menguji apakah benar ada pengaruh variable tertentu terhadap variable depeden misalnya yaitu dengan menguji hipotesis,
H0: βi = 0, lawan
HA: βi <, atau >, atau ≠ 0
Yaitu, kalau H0 diterima, maka tidak ada pengaruh variable dengan koefisien regressi βi terhadap variable dependennya, karena coefisien regressinya sama dengan nol sesuai dengan H0. Perhatikan, bi sebagai penduga dari βi yang didapatkan dari sample, most likely tidak akan sama dengan nol. Jadi kalau hasil uji hipotesis tidak significant, atau terima H0, tidak perlu lagi dibahas angka bi, apakah negative atau positif; itu harus dianggap sama dengan nol. Sebaliknya kalau H0 ditolak, maka dapat disimpulkan bahwa ada pengaruh yaitu sebesar bi, sebagai penduganya βi.
(Catatan: ingat bahwa yang kita uji adalah βi, yaitu coefisien regressi dari variable independent dari model yang merupakan abstraksi dari dunia nyata atau populasi – secara konvesi selalu diberi huruf Greek – . Karena populasi biasanya tidak pernah bisa kita ukur semua, maka untuk menguji kebenaran hipotesis pada level populasi seperti di atas, kita bekerja dengan sample, dan model dari sample menjadi menggunakan huruf biasa; misalnya bi sebagai penduga (estimator) dari βi. Mengenai cara menduga koefisien ini akan dibahas pada seri kedua dari tulisan ini).
Telandan 2 – Model Struktur Transformasi Digital: Telah kita lihat bagaimana memodel pertanyaan penelitian yang berkaitan dengan factor-faktor yang mempengaruhi permintaan terhadap suatu pproduk tertentu. Biasanya sejak awal telah kita abstraksikan satu struktur tertentu; lalu kita dalam model itu kita ingin tahu faktor-faktor mana yang mempengaruhi permintaan secara signifikan dan besar pengaruhnya. Pemodelan seperti ini selalu bermuara pada satu variable tertentu yang biasa disebut variable of main interest. Pada Teladadn 1, variabelnya adalah permintaan. Karena bermuara pada variable of main interest analisis seperti ini disebut juga Path Modeling (atau [ath analysis). Kalau main interet kita adalah variable-variabel apa saja yang terlibat atau yang menjadi komponen atau sub-komponen dari suatu system struktur, kemudian bagaimana hubuhgan interdependensi antara komponen (bahkan subsistem) dalam system itu, maka analisis ini adalah persoalan memilih satu model dari berbagai alternative sturktur yang mungkin dibangun mewakili dunia nyata. Latihan: coba bangun berbagai alternative struktur model arsitektur enterprise yang mengadopsi transformasi digital; definisikan komponen2nya/elemen2nya, hubungan interdependensi antara komponen; seperti apa struktur salah satu komponen misalnya, apakah ia merupakan satu sub system sendiri. Mungkin nanti bisa dibandingkan dengan Arsitektur Enterprise yang lama yang tanpa trnasformasi digital sebagai salah satu alternatif struktur. Lalu bisa dibandingkan, maka yang lebih cocok untuk menghadapi perubahan pada era industry 4.0 dimasa yang akan datang.
Bagaimana mengestimasi atau menduga persamaan regressi dan menguji hippotesis berdasarkan data dari sample akan diuraikan dalam tulisan seri berikutnya.
Model Untuk Latent (Non-observable) Variables
Pada prinsipnya pemodelan dengan Stuctural Equations (SEM) adalah seperti diuraikan di atas pada bagian pertama dari tulisan ini. Dalam ilmu statistika, pemodellan seperti ini lebih dikenal dengan nama Multivariate Statistical Analysis. Disebut Multivariate yang berbeda dengan simple dan multiple regression analysis karena pemodelan ini melibatkan lebih dari satu dependent variable (pada Gambar 3 misalnya Y dan P) tidak lagi berupa vector, tapi berupa matriks dan proses estimasi dilakukan secara simultan.
Tahapan selanjutnya adalah mengumpulkan data masing-masing variable lalu melakukan pengolahan data dan menarik kesimpulan. Perhatikan, variable-variabel Price (P), Income (I), Permintaan (Y) semuanya dapat diobservasi (observable variables). Yang tidak jarang terjadi, terutama dalam bidang ilmu-ilmu sosial, variabelnya tidak dapat diobservasi (non-observable), merupakan concept variable, atau kadang disebut latent variable. Sebagai contoh, kepuasan, tidak bisa diamati dan tentu diukur; demikian pula dengan loyalitas, juga tidak bisa diamati. Trust, Ease of use, usefulness, net-benefit, acceptance, dan banyak lagi yang lain, to name a few.
Untuk kasus model dengan variable yang non-observable ini maka harus ada tahap merumuskan instrument bagaimana mengukur Kepuasan atau Loyalitas misalnya. Alat ukur ini tetap disebut variable juga, yaitu operational variable, yaitu mengoperasionalkan variable konsep tersebut. Istilah lain yang juga sering digunakan adalah, indicator variable; yaitu yang mengidikasikan (maka sebutannya indicator) responden (objek yang akan kita ukur nantinya) yang Loyal misalnya atau yang Puas seperti apa. Karena indicator harus diukur, maka tidak boleh ada istilah konsep lagi, atau kata yang merupakan latent variable lagi dalam indicator tersebut. Harus kalimat yang pendek, gampang dimengerti, tidak ada istilah dalam bentuk konsep, dan yang sangat penting adalah sekali baca, responden harus bisa langsung memberi ukuran atau scale sebagai nilai pilihan dia untuk variable tersebut (bisanya menggunakan skala likert).
Untuk dapat menangkap persepsi respondent yang bergam terhadap makna dari variable konsep tersebut dengan baik, maka idealnya harus banyak indicator untuk tiap vaiabel latent/konsep. Tapi ada trade off antara yang ideal degan kesediaan responden mengisi indicator yang terlalu banyak. Rule of thumb nya adalah, apabila indicatornya dirancang atau diformulasikan dengan baik, maka miniun tiga indicator untuk masing-masing variable. Kenapa disarankan minimum tiga, karena dalam proses “massaging” the data, apabila ada indicator yang tidak valid, maka biasanya kita delete, lalu di-run lagi software-nya, agar masih ada tinggal dua indicator lagi; sebab kalau tinggal satu indicator, maka berarti kita menganggap variabel tersebut jadi observable; di samping akan ada masalah dalam proses pengolahan data statistiknya (masalah dalam matriks). Secara teoretis sebenarnya asal instrument itu di-design (consult expert in the field, misalnya) dengan baik sudah bisa dianggap valid; uji validitas sebenarnya untuk menyaring kemungkinan responden yang salah persepsi jadi salah ngisi jawaban.
Teladan 3 – Model Dengan Variable Latent: Katakanlah kita mau me-model atau mengabstraksikan factor-faktor apa saja yang menentukan Loyalitas di dunia nyata terhadap suatu produk tertentu misalnya. Seara teoritis, banyak sekali factor yang mempengaruhi Loyalitas. Bahkan menurut chaos theory (fractal), everything is dependent on everything. Tapi sebagai peneliti, anda bebas menentukan model anda – oleh karena itu sering disebut teori; dalam proposal Tesis, di bab 3.1. Kerangka Teori (teori anda); atau kadang disebut 3.1. The Model, atau 3.1. Framework Penelitian. Tujuannya nanti anda ingin mengecek apa teori anda ini benar dengan cara to test it against real data (sample) secara empiris (empirically). Lalu anda hipotesiskanlah bahwa Loyalitas ditentukan atau dipengaruhi oleh Kepuasan. Kerangka atau model ini dapat digambarkan sbb. (Gambar 5):
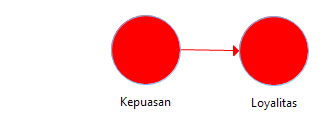
Gambar 5. Model Struktur Hubungan Kepuasan dan Loyalitas
Dari sudut SEM, model ini sudah selesai (disebut Sturctural Model) tinggal masuk pada pengumpulan data untuk selanjutnya diolah dan disimpulkan. Tapi angka atau pengamatan untuk kedua variable itu tidak ada (non-observable) (catatan, untuk variable yang non-observable konvensinya adalah menggunakan symbol bulat atau oval). Oleh karena itu kita ciptakanlah indicator untuk masing-masing variable tersebut, yaitu merancang dua pernyataan yang merupakan karakteristik dari pelanggan yang puas dan dua pernyataan yang merupakan karakteristik dari pelanggan yang loyal sebagai indikator atau operasional variabel. Pernyataan untuk kepuasan adalah (1) Para dokter memperlakukan pasien dengan baik (Doc), dan (2) Para perawat dan staf memperlakukan pasien dengan baik (Nur), yang diukur dengan skala Likert dari 1 sd 5 (1 = sangat tidak setuju, 5 = sangat setuju). Pernyataan untuk loyalitas adalah (1) Akan merekomendasikan produk ini kepada orang lain (Rec), dan (2) Akan membeli produk ini setiap kali memerlukan produk yang sama (Rev), juga dengan skala Likert 1 sd 5 ( 1 = sangat tidak mungkin, 5 = sangat mungkin sekali). Tahapan ini disebut Measurement Model. Selanjutnya model secara gambar menjadi sbb. (Gambar 6):
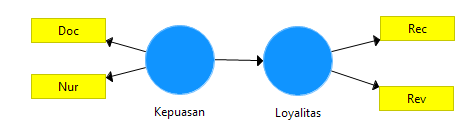
Gambar 6. Model Lengkap Hubungan Kepuasan dan Loyalitas
(Catatan, (1) konvensi secara umum pada SEM, untuk variable yang observable (seperti indicator), digambar dengan kotak; sedangkan untuk variable Latent (non-observable) digambar dengan bulatan atau oval. (2) Perhatikan, tidak ada tanda panah dari indicator ke variable dependen; oleh karena itu tidak bisa ditarik kesimpulan berkaian dengan pengaruh indicator terhadap variable dependen (dalam hal ini Loyalitas), dan ini terlihat pula dari persamaan regressi (6) di bawah, di mana tidak ada operational variable (indicator) pada persamaan struktur regressi tersebut.)
Sama seperti model hubungan Harga dengan Permintaan di atas, model struktur dari Kepuasan dan Loyalitas dapat dirumuskan dengan persamaan regressi sbb. (perhatikan dalam model sturktur, indicator tidak masuk):
` Loyalitas = β0 + β1 Kepuasan + ε . . . . . . . . . . . . . . . . . . (6)
Selanjutnya Model Pengukuran (Measurement Model) dapat dirumuskan dengan persamaan regressi sbb.:
Untuk Loyalitas terdapat dua persamaan regressi,
Rec = β10 + β11 Loyalitas + e1 ……………………………………………… (7)
Rev = β20 + β21 Loyalitas + e2 ……………………………………………….. (8)
Untuk Kepuasan juga terdiri dari dua persamaan regressi,
Doc = β30 + β31 Kepuasan + e3 …………………………………………….. (9)
Nur = β40 + β41 Kepuasan+ e4 ……………………………………………. (10)
Perhatikan, measurement model, yaitu persamaan (7), (8), (9) dan (10), merupakan persamaan regressi juga, di mana pada tahap ini yang dilakukan adalah (1) menguji apakah indicatornya valid merepresentasikan variable latennya, (2) apakah indicator-indikator itu reliable (konsisten), dan (3) menghitung nilai dari variable latennya yang merupakan rata-rata terbobot (weighted average) dari indicator-indikatornya. Secara statistika, tahap ini menggunakan Confirmatory Factor Analysis (CFA).
Konsep Dimensi
Kadang kala lebih mudah mengoperasionalisasikan variable konsep dengan memecah-mecahnya menjadi beberapa dimensi atau karakteristik kategori besar, dimana dimensi tersebut juga merupakan konsep. Lebih mudah maksudnya, bahwa lebih sederhana menciptakan pernyataan atau pertanyaan (indicator) yang dapat menangkap karakteristik dari dimensi, dibandingkan dengan merumuskan pernyataan atau pertanyaan yang dapat merefleksikan konsepnya. Perhatikan, dimensi hanya alat yang lebih memudahkan kita merumuskan indicator, bukan merupakan variable yang menjadi perhatian kita atau bagian dari pertanyaan penelitian. Oleh karena itu, yang dimasukkan dalam model pengukuran (Measurement Model) tetap indicator dari masing-masing dimensi tersebut.
Teladan 4 – Achievement motivation: achievement motivation adalah variable konsep dengan pengertian yang luas. Seringkali lebih mudah menentukan lebih dulu karekterstik seorang yang ber-achievement motivation yang tinggi dengan lebih dulu memecahnya menjadi beberapa dimensi yang lebih mudah dipahami sehingga lebih mudah merancang indikatornya. Orang dengan achievement motivation yang tinggi mungkin bisa memiliki karektersitik berikut: (1) gila kerja (workkoholic); (2) susah santai (unable to relax); (3) tidak sabar akan ketidakefektifan (impatience with ineffectiveness); (4) mengejar tantangan moderat (seeks moderate challenges). Dalam hal ini achievement motivation dipecah menjadi empat dimensi. Perhatikan, sekarang lebih mudah merumuskan indicator yang menjadi karaktersitik dari dimensi-dimensi tersebut. Sebagai contoh, tampak lebih mudah merumuskan tiga indicator misalnya untuk dimensi “gila kerja”, dengan (a) saya cenderung bekerja terus menerus, (b) saya enggan ambiI cuti, (c) semangat kerja tetap sekalipun banyak hambatan. Kalau masing-masing dimensi terdiri dari tiga indicator, maka total indicator untuk achievement motivation menjadi duabelas. Perhatikan, dalam hal ini kita tidak bisa menguji apakan dimensi tertentu mempengaruhi suatu dependen variable misalnya. Apabila kita ingin mengetahui apakah dimensi tertentu mempengaruhi dependen variable, maka pada model strukturnya harus ditarik panah dari setiap dimensi langsung ke dependen variabelnya dan variable achievement motivationnya diabaikan; sehingga kesimpulan kita misalnya, bila dimensi tertentu berpengaruh signifikan, menjadi: “dimensi …… dari achievement motivation mempengaruhi variable dependen”.
Latihan:
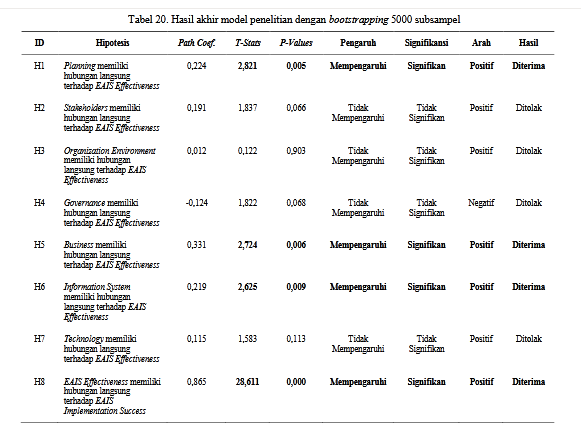
- Coba pelajari model di bawah ini. Berikan komentar berkaitan dengan model, dan tabal2 berikutnya.
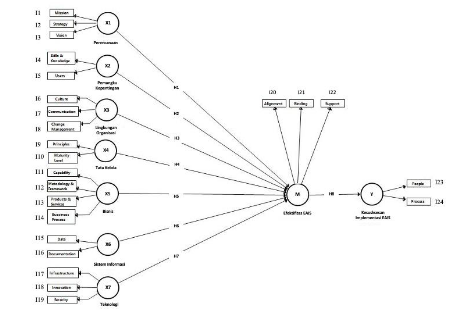
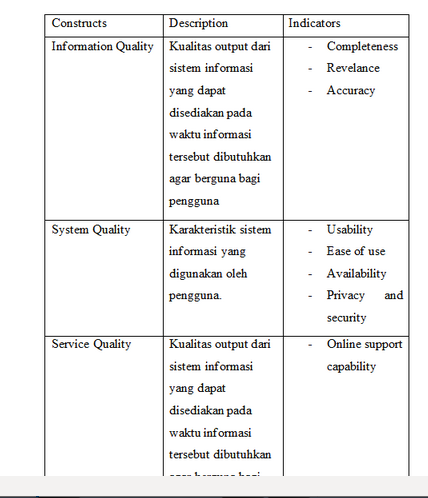
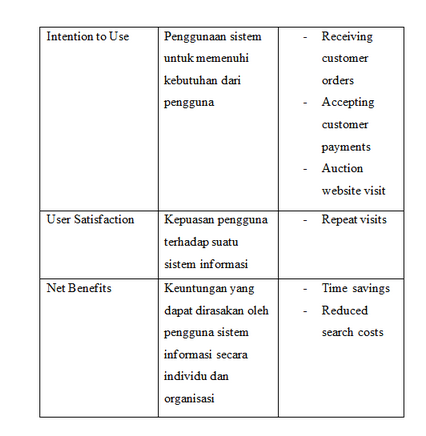
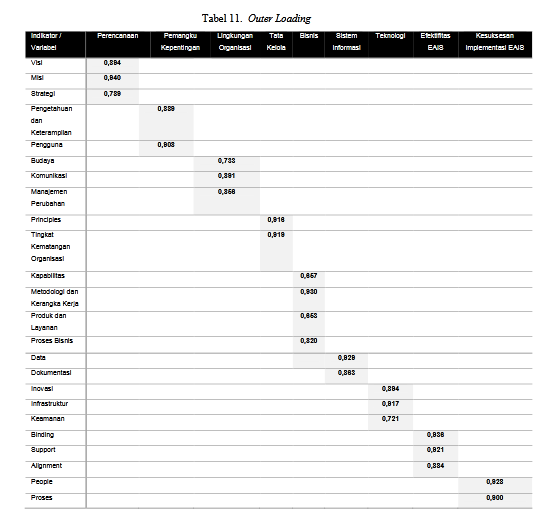
- Coba pelajari table berikut. Apa yang pelu disempurnakan dengan table tersebut?